Prestatiemeting Methode VERA
Prestatiemeting van uw corporatie. "Meten is weten" (maar wel met goede data!)
De VERA methodiek voor uitwerking van prestatie-indicatoren[bewerken | brontekst bewerken]
De koppelvlakdefinities geven technische definities van uitwisselingen in de vorm van fysieke schema’s en servicecontracten. De technische definities worden ook samengesteld op basis van de inhoud van de gegevensmodellen. VERA bevat vanwege deze relatie tussen gegevensmodellen enerzijds en kengetallen en koppelvlakken anderzijds daarom ook methodieken voor het uitwerken van kengetallen en koppelvlakdefinities. De methodiek voor koppelvlakdefinities maakt gebruik van StUF. Al deze onderdelen zijn weergegeven in onderstaande Figuur.
 Figuur 1: Detaillering onderdelen VERA procesinformatie.
Figuur 1: Detaillering onderdelen VERA procesinformatie.
In figuur 1 is de uitwerking van VERA voor de procesinformatie weergegeven. Voor de procesinformatie zijn (prestatie)indicatoren en kengetallen vanuit CORA gedefinieerd met de bijbehorende bedrijfs- en rekenregels. Hiervoor is nog een vertaling naar de techniek nodig die VERA geeft.
Deze vertaling bestaat uit stermodellen (feiten en dimensies) en een mapping die aangeeft hoe de feiten en dimensies tot stand komen op basis van de VERA entiteiten en attributen uit de logische gegevensmodellen.
Om de gegevens voor het vullen van de stermodellen uit de bronsystemen te kunnen halen bevat VERA voor de bronsystemen een standaard koppelvlak op basis van de VERA logische gegevensmodellen. Dit koppelvlak kan gebruikt worden door een ETL proces om de analyse- en rapportageapplicatie te vullen op basis van de mapping en modellen die VERA geeft voor de procesinformatie.
VERA beschrijft met name de methodiek om de definities die in CORA staan uit te werken zoals weergegeven in Figuur 2. Een resultaat van het volgen van de methodiek is dat er drie soorten koppelvlakken - zogenaamde adapters - zijn opgenomen: de basis-, ster- en datakluisadapter. Daarbij zijn uitwerkingen opgenomen van indicatoren zoals die in CORA zijn opgesteld.
- Beschreven wordt welke informatie-architectuur binnen VERA aanwezig is om PI berekeningen te faciliteren.
- Beschreven wordt welke methodiek gehanteerd wordt voor het berekenen van de VERA prestatie-indicatoren.
- Een voorbeeld-indicator is volledig uitgewerkt, waarbij alle stappen toegelicht worden.
- Een reeks indicatoren wordt kort uitgewerkt, waarbij alleen de laatste stappen uitgewerkt worden.
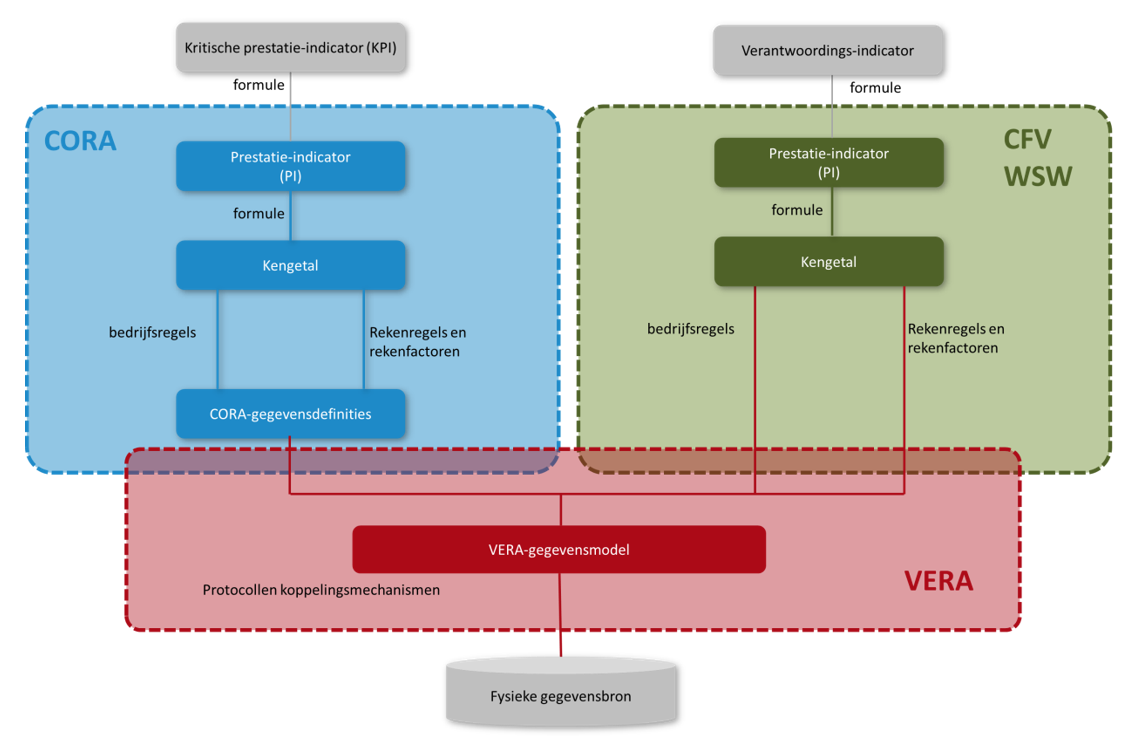 Figuur 2: Prestatie-indicatoren in CORA en VERA.
Figuur 2: Prestatie-indicatoren in CORA en VERA.
Welk probleem wordt opgelost?[bewerken | brontekst bewerken]
In de praktijk is het ontsluiten van de bestaande gegevensbronnen arbeidsintensief. Voor het produceren van sturingsinformatie gaat een groot deel van het werk zitten in “reversed engineering” om uit verschillende gegevensbronnen de juiste tabellen en velden te vinden met de juiste gegevens voor een meetwaarde.
Het introduceren van een standaard methodiek maakt deze “reversed engineering” overbodig voor de CORA meetwaarden en andere meetwaarden die met de methodiek zijn uitgewerkt. In de toekomst kunnen, door het standaardiseren vanuit de informatievraag, snel de gegevensonderdelen met hun specifieke kenmerken worden benoemd. Leveranciers kunnen deze gegevens dan vanuit de diverse gegevensbronnen aanbieden conform de methodiek.
Informatie-architectuur[bewerken | brontekst bewerken]
De VERA informatie-architectuur ten behoeve van prestatiemeting bestaat uit een aantal lagen met elk hun eigen functie. Dit is weergegeven in Figuur 3. De rode en groene blokken representeren lagen die onderdeel uitmaken van de VERA standaard, de grijze blokken zijn organisatie-specifiek. De verschillende lagen worden later individueel toegelicht.
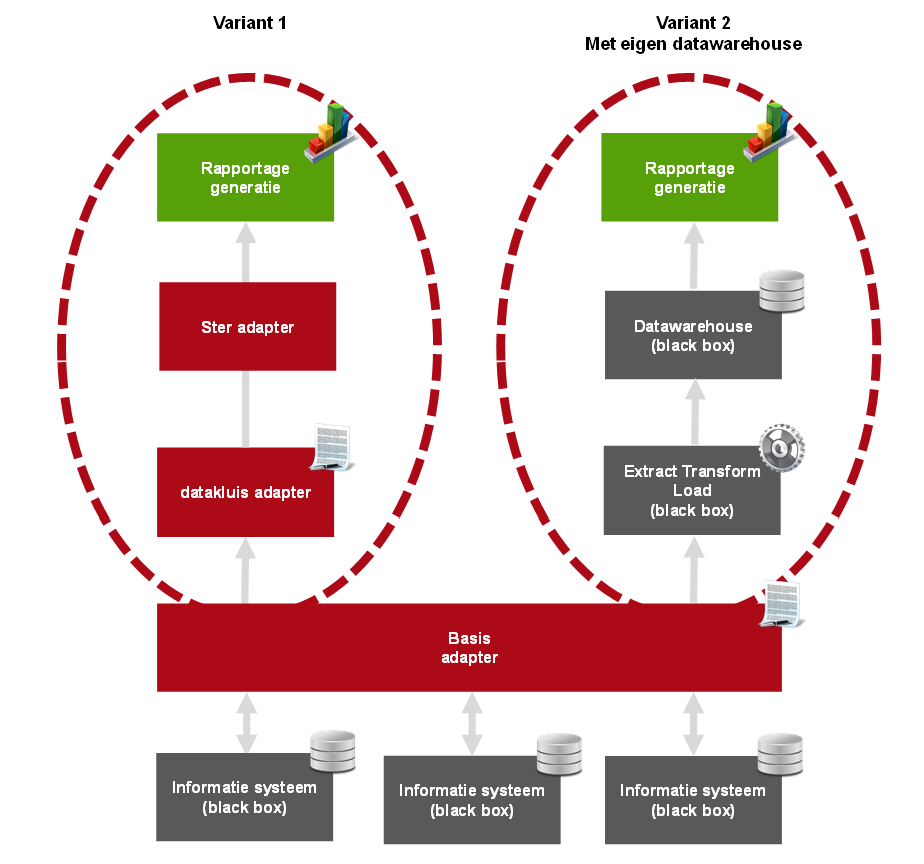 Figuur 3: VERA informatie-architectuur t.b.v. prestatiemeting.
Figuur 3: VERA informatie-architectuur t.b.v. prestatiemeting.
Zoals eerder is beschreven is de informatie-architectuur gericht op het faciliteren van het uitrekenen van prestatie-indicatoren. Voor veel prestatie-indicatoren zijn historische data nodig. De VERA informatie-architectuur is er dan ook op gericht om te voorzien in deze historische informatie en die op een zodanige manier aan te bieden dat het uitrekenen van de PI’s eenvoudig mogelijk wordt.
Traditioneel wordt historische informatie in een organisatie verzameld in een zgn. `data warehouse’. Sommige corporaties hebben al een data warehouse, andere niet. Voor corporaties die geen eigen data-warehouse hebben specificeert VERA twee lagen om deze historische dataopslag te verzorgen: de `Datakluis adapter’ en de `ster adapter’. Deze zijn onderdeel van `Variant 1’ in Figuur 3. Voor organisaties die wel een eigen data warehouse hebben specificeert VERA niet hoe de historische dataopslag vormgegeven moet worden, maar alleen hoe de uiteindelijke PI’s uitgerekend moeten worden: Het voorzien in de benodigde gegevens is dan een taak van het corporatiespecifieke datawarehouse. Dit is weergegeven in `Variant 2’ van Figuur 3.
De lagen in de informatie-architectuur hebben de volgende taken:
Basis adapter. Deze laag is verantwoordelijk voor het transformeren van een applicatie-specifiek gegevensmodel naar het VERA gegevensmodel. Het VERA gegevensmodel ondersteunt de processen uit CORA. De basisadapter levert gegevens aan per VERA klasse. Het is niet noodzakelijk dat de basisadapter alle klassen aanlevert. De gegevens die aangeleverd worden zijn bepaald door het gegevensdomein van het bronsysteem. Als de adapter gegevens over een klasse aanlevert dan dienen alle attributen van die klasse te worden aangeleverd, eventueel met lege waarden. (NULL-waarden.)
Datakluis adapter. Deze laag is verantwoordelijk voor het bijhouden van historische gegevens. Deze laag is alleen van toepassing voor corporaties die geen eigen data warehouse hebben. De Datakluis adapter leest gegevens uit via de basisadapter en slaat deze op in een relationele database volgens een vaste structuur die bekend staat als `Datakluis’ ofwel `datavault’. Deze adapter wordt verderop nader beschreven.
Ster adapter. De ster adapter is bedoeld om op een eenvoudige wijze rapportages te kunnen maken. Hoewel de Datakluis-adapter opslag van historische gegevens verzorgt leent deze laag zich niet voor rapportages. Sterschemas vormen een gebruikelijke vorm van data-modellering ten behoeve van rapportages. Een sterschema is een eenvoudig en overzichtelijk model dat bestaat uit een of meerdere feitentabellen die refereren aan dimensie tabellen waarop gebruikers op eenvoudige wijze met bijna iedere willekeurige rapportagetool kunnen rapporteren en analyseren. De ster adapter transformeert de gegevens uit de Datakluis adapter tot een sterschema. Deze adapter wordt verderop nader beschreven.
Per prestatie indicator wordt een sterschema gemaakt. Er zijn dus even veel ster adapters als indicatoren. Het is niet mogelijk om een algemeen recept te geven voor transformatie vanuit de Datakluis naar het sterschema: Deze transformatie zal voor elke indicator verschillend zijn. Verderop is echter wel per CORA indicator aangegeven welke dimensies en feiten/meetwaarden in de ster aanwezig moeten zijn om het berekenen van de betreffende indicator te ondersteunen.
Ook wanneer een corporatie een eigen datawarehouse omgeving gebruikt ligt het voor de hand dat sterschemas gebruikt worden. Deze zijn dan waarschijnlijk uitgebreider dan de microsterren die in het kader van VERA worden gedefinieerd en vormen daar een uitbreiding op. Niettemin kan ook in dit geval een sterschema gebruikt worden als basis voor het berekenen van de uiteindelijke indicator.
Rapportage generatie. In deze laag worden de prestatie indicatoren uitgerekend op basis van de ster adapters uit de vorige laag. Dit behelst doorgaans het aggregeren van gegevens in een ster adapter en het uitvoeren van een berekening op de geaggregeerde gegevens. Deze berekeningen zijn verderop weergegeven onder `formule’.
Samenvattend kan men zeggen dat de basisadapter is bedoeld om op gestandaardiseerde wijze data aan te leveren en de Datakluis adapter om hiervan historie bij te houden. De presentatie van de gegevens in deze lagen is niet gebruiksvriendelijk genoeg voor rechtstreekse rapportages, dat is de taak van de ster adapter. De feitelijke prestatie indicatoren worden vervolgens in de rapportage generatie-laag berekend.
Datakluis adapter[bewerken | brontekst bewerken]
De Datakluis adapter (Linstedt, 2010) volgt een vaste systematiek voor het transformeren van gegevens uit de VERA basisadapter naar een Datakluis architectuur. Een Datakluis is een relationeel datamodel waarin drie typen tabellen aanwezig zijn: hubs, links en satellites. Zij zijn op eenvoudige wijze te creëren uit het VERA klassenmodel en bieden opslag van historische gegevens.
Kortweg kan men zeggen dat hub- en linktabellen de structuur van de gegevens bevatten: welke objecten (hebben) bestaan in het domein en hoe is de associatiestructuur tussen deze objecten (geweest)? Satellite-tabellen bevatten de attributen van de objecten: De eigenlijke gegevens. Men kan `hubs en links’ vergelijken met metadata, `satellites’ met data. Een gedetailleerdere beschrijving is als volgt:
Hubs leggen vast welke objecten een rol spelen in het business domein. Per klasse (entiteit type) is er één hub-tabel. Binnen het VERA klassenmodel zijn bijvoorbeeld de klassen Overeenkomst, Huurovereenkomst en Huurgeschil aanwezig. Voor al deze klassen zal een hubtabel worden aangemaakt. Per object (instantie, record) van een klasse is er één rij in de betreffende hubtabel. Een hubtabel bevat de volgende typen kolommen:
- Artificial key. (not null, unique.) Een kunstmatige sleutel (bijvoorbeeld een automatisch gegenereerd nummer) die fungeert als primary key voor de hubtabel.
- Business key. (not null, unique, een of meer kolommen.) Een natuurlijke sleutel die in het gegevensdomein wordt gebruikt om instanties mee te onderscheiden. Bijvoorbeeld BSN. Een business key kan uit meerdere kolommen bestaan. De businesskey-attributen worden overgenomen uit het VERA klassenmodel.
- Record source. (not null.) De bron waaruit de betreffende rij het eerst is geladen.
- Audit id. Een optionele verwijzing naar een tabel met audit informatie.
De naamgevingsconventies voor de hubtabel die binnen VERA gehanteerd worden zijn weergegeven in Figuur 4. In deze tabel staan de naamgevingsregels in de linkerkolom en staat een uitgewerkt voorbeeld in de rechterkolom.
 Figuur 4: Naamgevingsconventies voor hubtabellen.
Figuur 4: Naamgevingsconventies voor hubtabellen.
Links leggen vast welke associaties (relationships1) er bestaan tussen de klassen. Per associatie tussen twee klassen zijn er één of twee linktabellen. Een linktabel verwijst naar twee hubtabellen.2 Een linktabel die de hubs h1 en h2 verbindt bevat de volgende typen kolommen:
- Artificial key. (not null, unique.) Een kunstmatige sleutel (bijvoorbeeld een automatisch gegenereerd nummer) die fungeert als primary key voor de linktabel.
- Foreign key h1. (not null.) Verwijzing naar een rij uit hubtabel h1.
- Foreign key h2. (not null.) Verwijzing naar een rij uit hubtabel h2.
- Record source. (not null.) Bron waaruit de betreffende rij het eerst is geladen.
- Audit id. Optionele verwijzing naar een tabel met audit informatie.
(Het is conceptueel mogelijk dat er meer dan twee hubs verbonden worden met een linktabel. In dat geval zijn er meer dan twee foreign keys aanwezig. Binnen VERA komt dit echter niet voor.)
In het VERA klassenmodel zijn associaties binnen een klasse te herkennen als attributen van een type uit het VERA gegevensmodel. Bijvoorbeeld het attribuut huurgeschil binnen de klasse Huurovereenkomst is van de domein specifieke klasse Huurgeschil. In de Datakluis bestaat daarom een linktabel die Huurovereenkomst en Huurgeschil met elkaar verbindt.
Binnen VERA zijn zowel bi- als unidirectionele associaties tussen klassen aanwezig. In het geval van een bidirectionele associatie is in beide klassen die bij de associatie zijn betrokken een attribuut opgenomen dat de associatie representeert, in het geval van een unidirectionele associatie is zo’n attribuut maar aan een zijde aanwezig.3 Iedere zijde van een associatie wordt in de VERA Datakluis gerepresenteerd door een aparte linktabel. Bidirectionele associaties leiden dus tot twee linktabellen, unidirectionele associaties tot een linktabel.
Linktabellen zijn vergelijkbaar met `kruistabellen’ die in een 3NF database gebruikt worden om N:M associaties mee te modelleren. Merk op dat ook 0-1, 1-1 en 1-M associaties vastgelegd worden met linktabellen, terwijl deze in een 3NF database worden opgenomen als foreign keys in de tabel van een verwijzende klasse samen met de business key (hub) en de overige attributen (satellite).
De naamgevingsconventies voor linktabellen binnen VERA zijn weergegeven in Figuur 5. Links staat weer de regel, rechts een uitgewerkt voorbeeld. Dit voorbeeld betreft een bidirectionele associatie, die leidt tot twee linktabellen.
 Figuur 5: Naamgevingsconventies voor linktabellen.
Figuur 5: Naamgevingsconventies voor linktabellen.
Satellites leggen vast welke gegevens verder van toepassing zijn op de objecten en de associaties uit de hub- en linktabellen. Een satellitetabel verwijst naar één hubtabel of één linktabel. Een satellitetabel bevat de volgende typen kolommen:
- Artificial key. (not null, unique.) Een kunstmatige sleutel (bijvoorbeeld een automatisch gegenereerd nummer) die fungeert als primary key voor de satellitetabel.
- Foreign key. (not null.) Verwijzing naar een rij uit hubtabel of linktabel waarop de informatie uit dit record van toepassing is.
- Attr1, Attr2, Attr. etc.: Kolommen met inhoudelijke attributen.
- Load start date. Begindatum voor de geldigheid van deze rij uit de satellitetabel.
- Load end date. Einddatum voor de geldigheid van deze rij uit de satellitetabel.
- Record source. (not null.) Bron waaruit de betreffende rij het eerst is geladen.
- Audit id. Optionele verwijzing naar een tabel met audit informatie.
Voor elke hub wordt een satellitetabel aangemaakt. Bijvoorbeeld voor de VERA-klasse Huurovereenkomst bevat de satellitetabel de volgende kolommen voor de inhoudelijke attributen: waarborgsom, waarborgsomRente, opzegdatum, btw, prolongatieInterval, etc.
Ook voor elke link wordt een satellitetabel aangemaakt. Deze bevat informatie over de geldigheid van de associatie.
De naamgevingsconventies voor satellitetabellen zijn weergegeven in Figuur 6 en 7.
 Figuur 6: Naamgeving sat tabellen op hubs.
Figuur 6: Naamgeving sat tabellen op hubs.
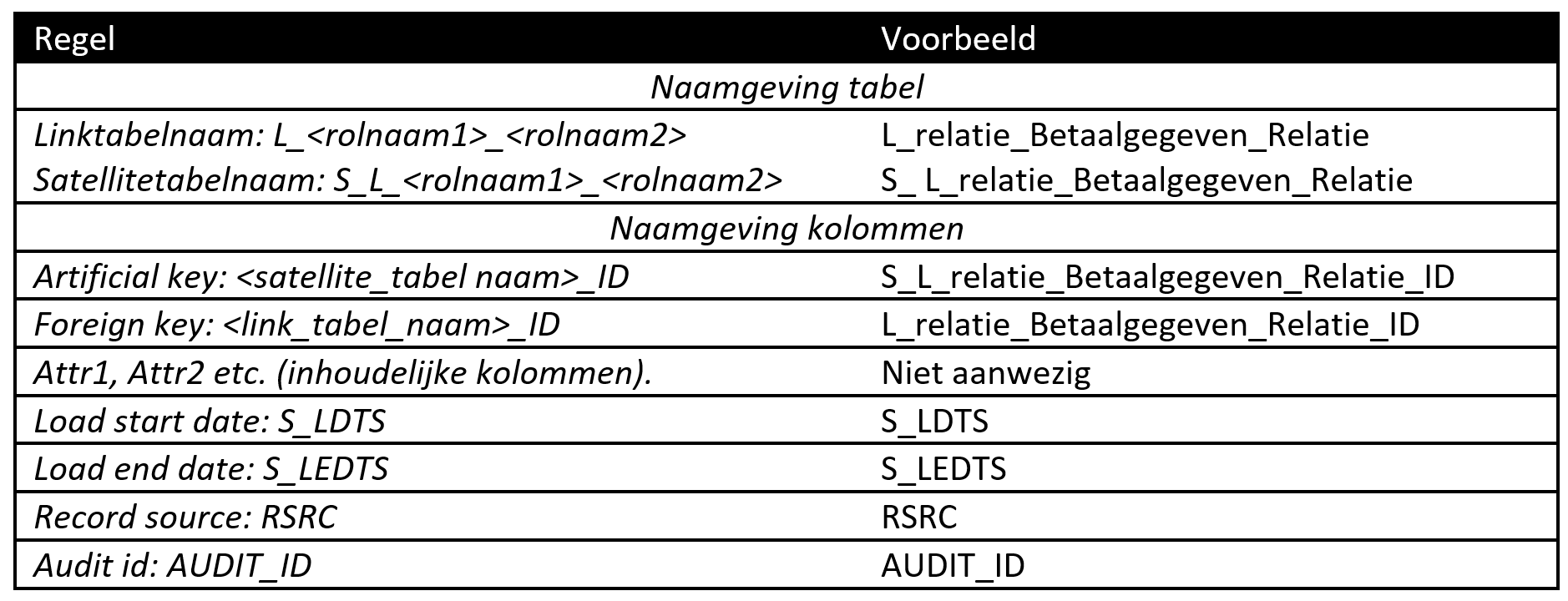 Figuur 7: Naamgeving voor sat tabellen op links.
Figuur 7: Naamgeving voor sat tabellen op links.
Inheritance[bewerken | brontekst bewerken]
Binnen het VERA klassenmodel bestaan klassen die subklassen zijn van andere klassen. Bijvoorbeeld ` Huurovereenkomst’ is een subklasse van ` Overeenkomst’. In zo’n geval wordt een aparte hub en een aparte satellite aangemaakt voor de subklasse. In de hub wordt de businesskey van de superklasse gebruikt als business key. In de satellite voor de hub worden alle simpele attributen uit de superklasse opgenomen. Deze worden dus gedupliceerd. Daarentegen worden de associaties van de superklasse slechts een keer gerepresenteerd: Alleen voor de superklasse.
Tijdens het laden van de Datakluis worden objecten van een subklasse zowel in de superklasse-tabellen als in de subklasse-tabellen opgenomen.
Meerdere bronnen[bewerken | brontekst bewerken]
Wanneer er meerdere bronsystemen zijn die een (gedeeltelijk) overlappend gegevensmodel hebben dan leidt dat tot aparte satellitetabellen en aparte linktabellen voor elk systeem. Per klasse wordt echter maar één hubtabel aangemaakt.
Bijvoorbeeld: Een woonruimte verdeel-systeem (WRV) en een primair systeem (ERP) leveren beide gegevens aan over o.a. Relatie en Betaalgegeven. Er bestaat een associatie (one-to-many) tussen Relatie en Betaalgegeven. Dit wordt op de volgende wijze in de Datakluis verwerkt.
- Er wordt één hub aangemaakt voor Relatie en één voor Betaalgegeven. Deze heten H_Relatie en H_Betaalgegeven.
- Er worden twee satellites aangemaakt voor Relatie, voor elke bron een. Deze heten S_H_Relatie_1 en S_H_Relatie_2. Idem voor Betaalgegeven.
- Er worden twee linktabellen aangemaakt: Voor elke bron een. Deze heten L_relatie_Betaalgegeven_Relatie_1 en L_relatie_Betaalgegeven_Relatie_2.
- Om wijzigingen in de geldigheid van de links bij te houden worden twee `link satellite’ tabellen aangemaakt: Voor elke bron één. Deze heten S_L_relatie_Betaalgegeven_Relatie_1 en S_L_relatie_Betaalgegeven_Relatie_2.
Merk op dat de naam van de bron niet in de naam van de tabellen wordt verwerkt. De naam van de bron staat echter in de tabel zelf.
In de situatie dat meerdere bronnen gegevens aanleveren over dezelfde objecten moet een rangorde aan de bronnen gegeven worden om te kunnen bepalen welke bron het meest betrouwbaar is voor een bepaald type gegeven. Deze rangorde is organisatie specifiek. VERA faciliteert het vastleggen van deze rangorde door een tabel SourceRankOrder waarin de rangorde kan worden vastgelegd:
 Figuur 8: SourceRankOrder tabel om rangorde belangrijkheid van bronnen voor attributen vast te leggen wanneer er overlappende bronnen zijn.
Figuur 8: SourceRankOrder tabel om rangorde belangrijkheid van bronnen voor attributen vast te leggen wanneer er overlappende bronnen zijn.
Merk op dat de kolom hub redundant is omdat deze ook uit de satellite achterhaald kan worden. Deze kolom is dan ook afgeleid. Verder is de combinatie satellite, attribuut en rangorde uniek.
Ster adapter[bewerken | brontekst bewerken]
Zoals eerder gezegd definieert VERA per prestatie-indicator een sterschema dat de berekening van deze indicator ondersteunt. Per indicator zal de benodigde transformatie vanuit de Datakluis verschillen en het is daarom niet mogelijk om hier een algemeen recept voor te geven. In deze paragraaf lichten we echter in algemene termen het sterschema toe. Het sterschema staat ook bekend als `dimensioneel model’ in de literatuur.
Een sterschema is een relationeel datamodel. Binnen een sterschema bestaan twee typen tabellen: feittabellen en dimensie-tabellen. De feittabellen bevatten informatie over gebeurtenissen die in het domein hebben plaatsgevonden, bijvoorbeeld `verhuringen’, `verkopen’ of `klachten’. Eén zo’n gebeurtenis noemt men een feit. Ook bevatten de feittabellen numerieke gegevens die geassocieerd zijn met deze gebeurtenissen, bijvoorbeeld `verkoopopbrengsten’. Deze numerieke gegevens worden meetwaarden of measures genoemd. Dimensie-tabellen bevatten (hoofdzakelijk) niet-numerieke gegevens die met een feit zijn geassocieerd. Bijvoorbeeld postcode, woonplaats, huisnummer en woningtype die van toepassing zijn op een verkochte woning. Vanuit een feittabel zijn er doorgaans verwijzingen naar meerdere relevante dimensie-tabellen. Wanneer men dit visueel weergeeft heeft het schema de vorm van een ster, vandaar de naam sterschema. Een voorbeeld is weergegeven in Figuur 4.2 op pagina 21.
Binnen VERA hanteren we de conventie dat de naam van feittabellen met Feit begint en dat de naam van dimensie tabellen met Dim begint, bijvoorbeeld: DimTijd en FeitAantalLeegstandsDagen, zie Figuur 4.2 in Paragraaf 4.4.
Feittabellen. In een feittabel worden gegevens op het laagste niveau opgeslagen, geen geaggregeerde gegevens. Wanneer een feittabel aantallen bevat dan hebben deze op het laagste niveau veelal waarden 0 of 1, bijvoorbeeld het aantal leegstandsdagen van een specifieke VHE op een specifieke dag. Met behulp van een rapportage-tool kan men dan aggregeren over dimensies.
Voor veel van de indicatoren is aggregeren van feiten en meetwaarden over dimensies niet voldoende en moet een ratio berekend worden. (Een voorbeeld is leegstandspercentage.) Het berekenen van deze ratio vindt plaats in de rapportage-laag.
Dimensie tabellen zijn niet genormaliseerd. Daar waar je een transactiemodel normaliseert doe je dat in een microstermodel juist niet; het sterschema is juist zoveel mogelijk plat om heel snel data te kunnen selecteren. Het maakt de ster helderder.
De attributen in de dimensietabellen binnen een ster zijn één op één gelijk aan de attributen uit specifieke VERA-klassen en dus ook aan de attributen uit de satellitetabellen van de Datakluis. Zo is het attribuut DimEenheid.adres gelijk aan het attribuut Eenheid.adres en het attribuut DimEenheid.id is gelijk aan het attribuut Eenheid.id. Dat impliceert dat ook het gegevenstype van deze attributen steeds één op één gelijk is. Gevolg is dat de sleutel van iedere dimensieklasse van het type String is en niet van het meer gebruikelijke type Integer.
Het woord micro in de term microster drukt uit dat voor een prestatie-indicator de minimale verzameling attributen is opgenomen die nodig is voor het berekenen van de betreffende PI.
Van CORA naar de VERA methodiek voor stuuringsinformatie[bewerken | brontekst bewerken]
Zoals eerder vermeld is in CORA 3.0 is een methodiek voor de uitwerking van prestatie-indicatoren naar kengetallen opgenomen en is voor de processen Verkoop en Verhuur een reeks prestatie-indicatoren uitgewerkt (NetwIT, 2012, p. 101). Deze methodiek behelst kortweg het toepassen van `bedrijfsregels’ en `rekenregels’ op het CORA-gegevensmodel. Voor meer informatie verwijzen we naar CORA 3.0.
CORA-voorbeeld[bewerken | brontekst bewerken]
De CORA methodiek voor het berekenen van een prestatie-indicator laat zich het eenvoudigst uitleggen aan de hand van een voorbeeld. Onderstaand voorbeeld is afkomstig uit CORA 3.0 (NetwIT, 2012, p. 222).
 Figuur 9: Voorbeeld indicator CORA 3.0
Figuur 9: Voorbeeld indicator CORA 3.0
In dit voorbeeld wordt een KPI `Afnamesnelheid van de leegstand’ gedefinieerd. Deze is gebouwd op twee `Kengetallen’: A en B. Elk kengetal wordt gespecificeerd als de uitkomst van een berekening op onderliggende gegevens: Deze berekening is beschreven onder `Rekenregels’. Er kunnen condities aan de data die gebruikt worden in de berekening worden opgelegd onder `Bedrijfsregels’.
Uitwerking methodiek binnen VERA[bewerken | brontekst bewerken]
Zoals eerder opgemerkt volgt VERA de CORA methodiek voor het berekenen van prestatie indicatoren, d.w.z. het maakt gebruik van bedrijfsregels, rekenregels, kengetallen en formules. Binnen VERA wordt deze methodiek echter concreter uitgewerkt dan in CORA omdat de relatie met het onderliggende VERA klassenmodel tot stand wordt gebracht. De term kengetal wordt binnen VERA vervangen door `meetwaarde’ om aansluiting te verkrijgen bij de standaard terminologie binnen het data-warehousing vakgebied: De CORA kengetallen komen als `meetwaarden’ in de feitentabellen van VERA terecht.
De methodiek voor het uitwerken van een indicator bestaat uit de volgende stappen, die voor elke indicator afzonderlijk uitgevoerd worden:
- Analyse van de indicator. In deze stap wordt de vraag beantwoord welke gegevens nodig zijn voor de bedrijfs- en rekenregels en voor de dimensies. Dit is om te toetsen of de bestaande gegevensmodellen uit VERA voldoen om waarden van CORA-kengetallen te kunnen tonen. Immers, om die waarden te tonen is het nodig dat vanuit de CORA-gegevensdefinities de juiste attributen in de VERA-modellen aanwezig zijn.
- Uitbreiding VERA-klassenmodel (ontwerp Basisadapter). Voor de Basis adapter wordt het VERA-klassenmodel uitgebreid met klassen en attributen die ontbreken voor de betreffende indicator.4
- Ontwerp Datakluis adapter. Op basis van het aangepaste klassenmodel wordt volgens de systematiek uit Sectie 2.1 de structuur voor een Datakluis gegenereerd, of worden de relevante tabellen in een reeds bestaande Datakluis geidentificeerd. In de Datakluis wordt de opslag van historische gegevens verzorgd.
- Ontwerp Ster adapter. Vervolgens wordt een sterschema gespecificeerd ter ondersteuning van de berekening van de betreffende indicator. De transformatie van Datakluis naar sterschema is per indicator verschillend en wordt dus per indicator uitgewerkt. Elke ster bevat een of meer `meetwaarden’ in de feiten tabel. Deze meetwaarden komen tot stand door het toepassen van bedrijfsregels en rekenregels op de onderliggende gegevens uit de Datakluis. De meetwaarden zijn dus het VERA equivalent van de CORA kengetallen.
- Berekening prestatie indicator. Als laatste stap wordt de uiteindelijke indicator berekend o.b.v. de in het sterschema aanwezige gegevens. Dit berekenen gebeurt door het toepassen van een formule op de onderliggende meetwaarden.
Ad 5: Binnen VERA staan rekenregels en bedrijfsregels los van de toepassing in de berekening van een prestatie indicator. Rekenregels en bedrijfsregels hebben binnen VERA een nummer.
Bijvoorbeeld BR182 = “Overeenkomst is een huurovereenkomst” of RR161 = ”Som van aantal overeenkomsten”. Dit komt de herbruikbaarheid ten goede, bij gebruik van zo’n reken- of bedrijfsregel in een berekening kan dan volstaan worden met een verwijzing naar het nummer. Dat is compacter dan volledig uitschrijven. Ook is het op deze wijze eenvoudig om aanpassingen in een reken- of bedrijfsregel `uit te rollen’ over alle plaatsen waar die regel gebruikt wordt. Een voorbeeld-situatie waarin dit zinvol zou kunnen zijn is wanneer de definitie van DAEB woningen zou wijzigen en deze gewijzigde definitie geëffectueerd moet worden in verschillende meetwaarden.
Verderop zien we een aantal uitgewerkte prestatie indicatoren. In deze uitwerkingen worden de bovenstaande stappen doorlopen. Hierbij moet de kanttekening worden gemaakt dat de Datakluis laag (stap 3) en de aansluiting tussen de Datakluis en het sterschema (stap 4) nog niet volledig uitgewerkt zijn. Dit is een gevolg van het verloop van het VERA traject. Voor deze uitwerking doet de werkgroep een RFC, zodat in een volgende versie de stermodellen aansluiten op de onderliggende Datakluis.
Bij wijze van voorbeeld zijn alle stappen uitgewerkt met toelichting voor een eenvoudige prestatie indicator.
Voorbeelduitwerking indicator[bewerken | brontekst bewerken]
Als voorbeeld is de indicator ‘Aantal leegstandsdagen’ uitgewerkt. Onderstaande tabel is overgenomen uit (NetwIT, 2012)
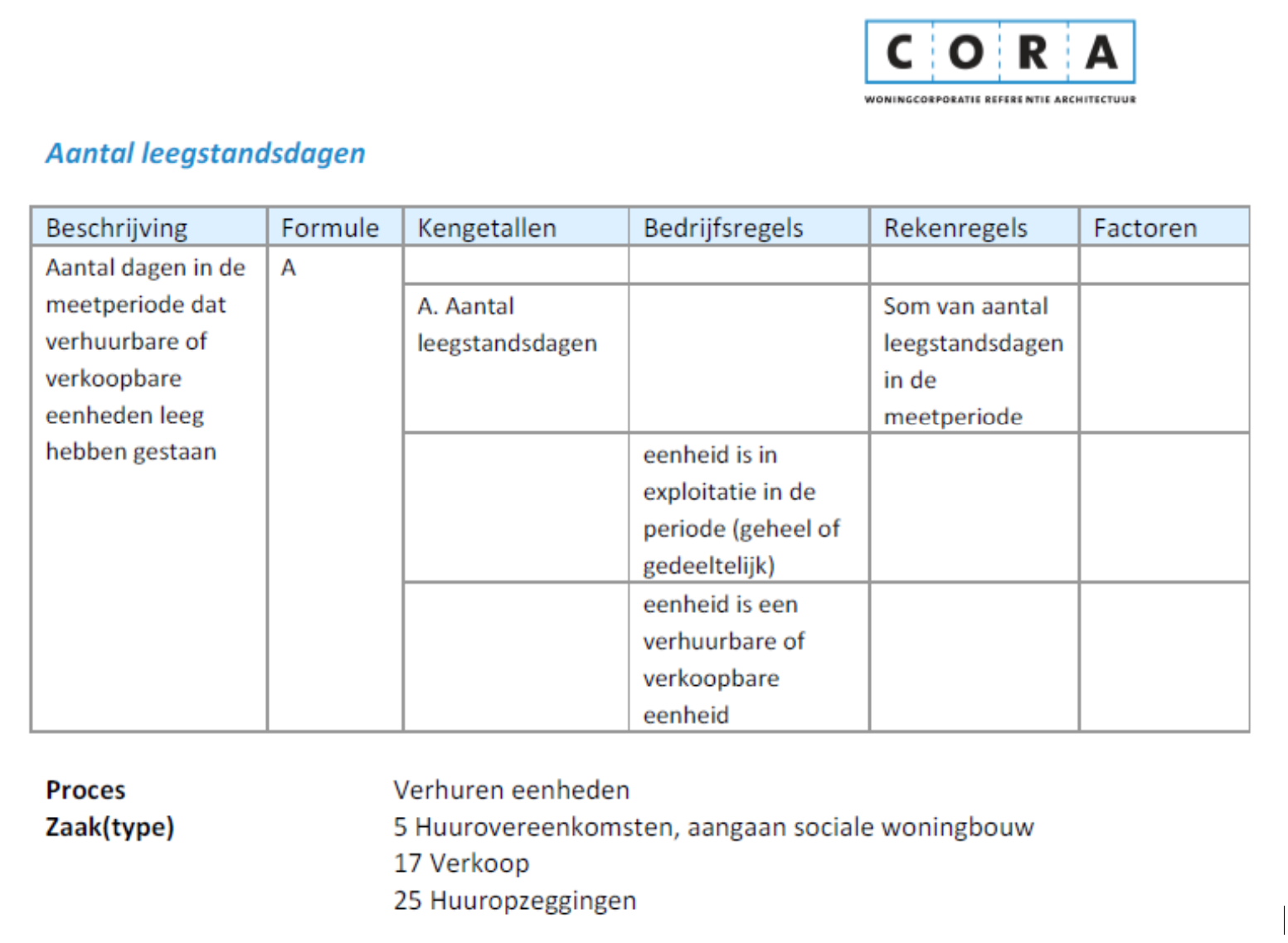 Figuur 10: Opbouw indicator aantal leegstandsdagen volgens CORA.
Figuur 10: Opbouw indicator aantal leegstandsdagen volgens CORA.
Voor deze indicator worden alle stappen doorlopen.
Stap 1: Analyse van de indicator[bewerken | brontekst bewerken]
Van elk van de genoemde bedrijfsregels en rekenregels is het volgende getoetst: welke klasse wordt geraakt, wat zijn de benodigde attributen en zijn die aanwezig in VERA? Deze toetsing wordt per meetwaarde herhaald. (In het voorbeeld is maar één meetwaarde nodig voor het uitrekenen van de prestatie indicator.) Met het resultaat van deze toetsing kan stap 2 worden uitgevoerd.
- Meetwaarde A
- Aantal leegstandsdagen. (Aantal dagen in de meetperiode dat verhuurbare of verkoopbare eenheden leeg hebben gestaan.)
De inventarisatie van benodigde attributen voor de rekenregel is in onderstaande tabel gegeven.
 Figuur 11: Inventarisatie attributen rekenregels.
Figuur 11: Inventarisatie attributen rekenregels.
De inventarisatie van benodigde attributen voor de bedrijfsregels is in onderstaande tabellen gegeven.
 Figuur 12: Inventarisatie attributen bedrijfsregels.
Figuur 12: Inventarisatie attributen bedrijfsregels.
Geconcludeerd mag worden dat het VERA klassenmodel toegerust is om te voorzien in de informatie die nodig is voor deze prestatie indicator.
Stap 2: Uitbreiding VERA klassen: Basisadapter[bewerken | brontekst bewerken]
In de vorige stap zijn geen benodigde attributen naar voren gekomen die ontbreken binnen VERA. De VERA klassen hoeven daarom niet uitgebreid te worden. Deze stap kan dus overgeslagen worden. Wanneer er wel ontbrekende attributen aan het licht komen worden deze d.m.v. een RFC aan Stichting VERA gecommuniceerd.
Stap 3: Ontwerp Datakluis adapter[bewerken | brontekst bewerken]
Het ontwerp van de Datakluis adapter behelst het toepassen van de in eerder genoemde regels en naamgevingsconventies.
In het kader van dit voorbeeld beperken we de opbouw van de Datakluis tot de hierboven geïdentificeerde klassen: Eenheid en EenheidToestand. Van deze klassen zijn slechts zeven attributen nodig voor het berekenen van de prestatie indicator. In de datavault worden echter alle attributen opgenomen.
De attributen in het VERA klassenmodel kunnen verwijzen naar andere VERA klassen, in het geval van associaties, of het kunnen enkelvoudige attributen zijn (simple attributes.) In het kader van deze voorbeelduitwerking worden de enkelvoudige attributen in de data vault opgenomen maar van de associaties wordt alleen de associatie tussen Eenheid en EenheidToestand opgenomen. De resterende attributen zijn deels weergegeven in Figuur 13 en 14. Voor de betekenis van deze velden en de overige attributen verwijzen we naar de VERA documentatie.
 Figuur 13: Enkelvoudige attributen (simple attributes) van de Eenheid-klasse gebruikt in het voorbeeld voor de Datakluis.
Figuur 13: Enkelvoudige attributen (simple attributes) van de Eenheid-klasse gebruikt in het voorbeeld voor de Datakluis.
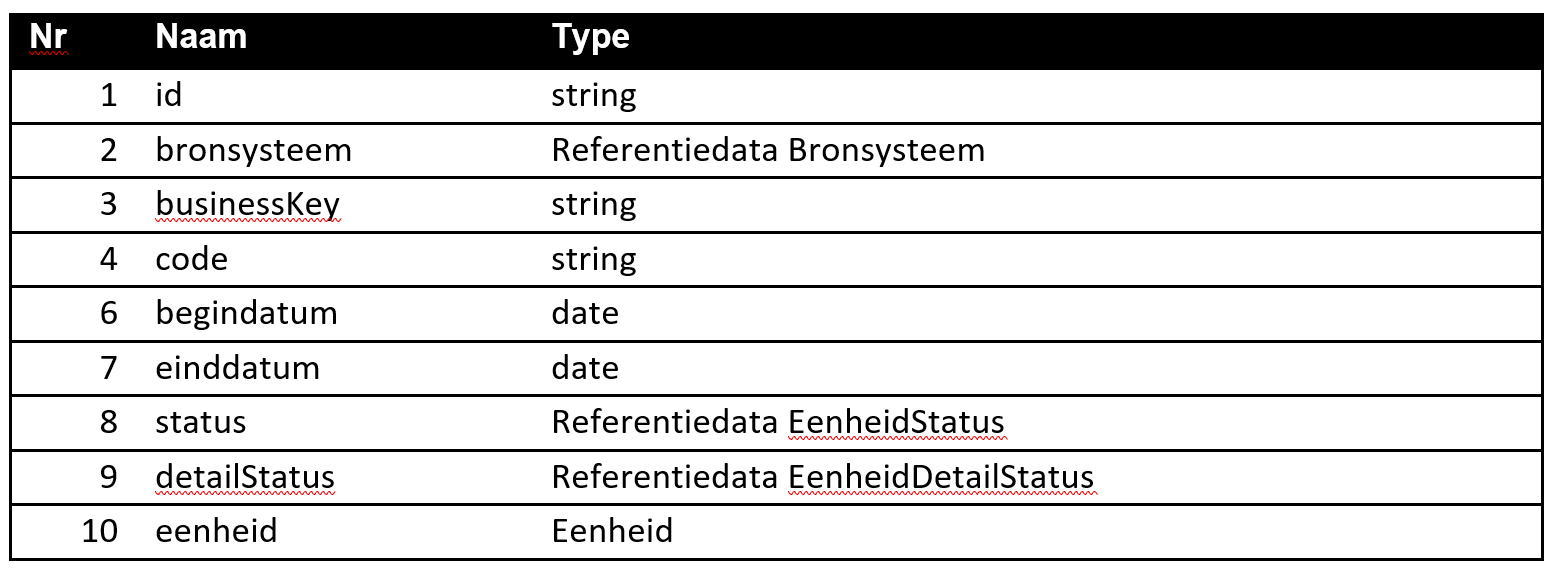 Figuur 14: Enkelvoudige attributen (simple attributes) van de klasse EenheidToestand.
Figuur 14: Enkelvoudige attributen (simple attributes) van de klasse EenheidToestand.
Met deze klassen en attributen wordt het database schema gemaakt dat is weergegeven in Figuur 15. Het is belangrijk om te vermelden dat deze figuur slechts een klein deel van de volledige VERA-Datakluis laat zien. In de volledige Datakluis zijn hubtabellen met veel andere tabellen verbonden afhankelijk van de associaties in het datamodel. Het is dus niet zo dat voor elke indicator een aparte Datakluis gemaakt wordt, zoals dat voor de sterschemas (volgende stap) wel gebeurt.
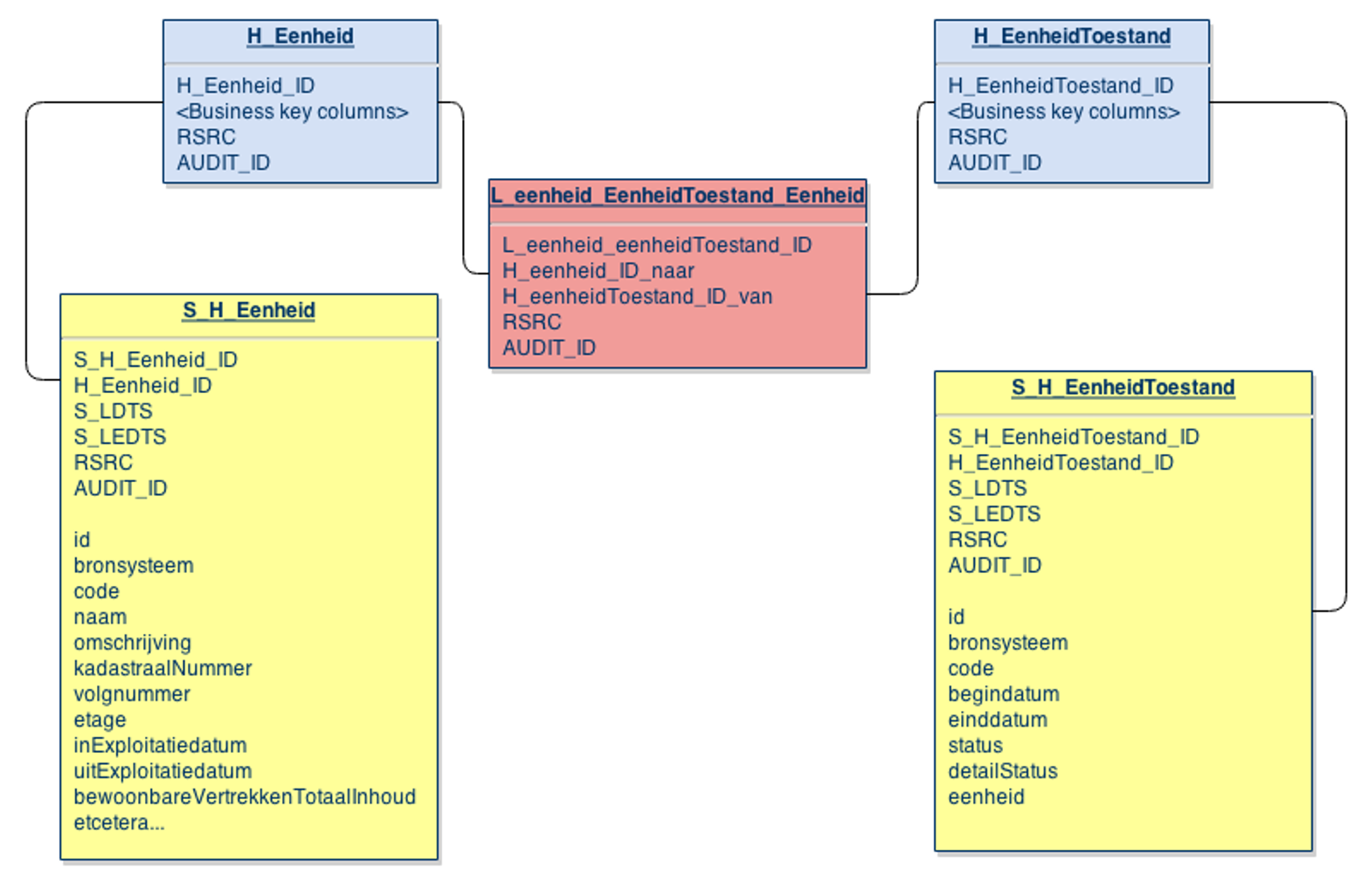 Figuur 15: Schema voor Datakluis adapter voorbeeld indicator.
Figuur 15: Schema voor Datakluis adapter voorbeeld indicator.
Stap 4: Ontwerp ster adapter[bewerken | brontekst bewerken]
In deze paragraaf wordt een `sterschema’ gedefinieerd waarmee de indicator `aantal leegstandsdagen’ uitgerekend kan worden. De meetwaarden in de ster worden berekend op basis van de in de Datakluis aanwezige gegevens. Zoals eerder gezegd is de aansluiting tussen de Datakluis en het sterschema nog niet uitgewerkt in deze versie van VERA. Wel is de definitie van de meetwaarden in de feiten-tabel op basis van het VERA gegevensmodel uitgewerkt voor alle voorbeelden in de bijlagen. De eerste uitgewerkte indicator in deze paragraaf is `Aantal Leegstandsdagen’.
Met betrekking tot de definities van de meetwaarden verwijzen we op dit punt naar de uitwerking in de bijlagen. We volstaan hier met het tonen van het resulterende sterschema. Dit schema is weergegeven in Figuur 16.
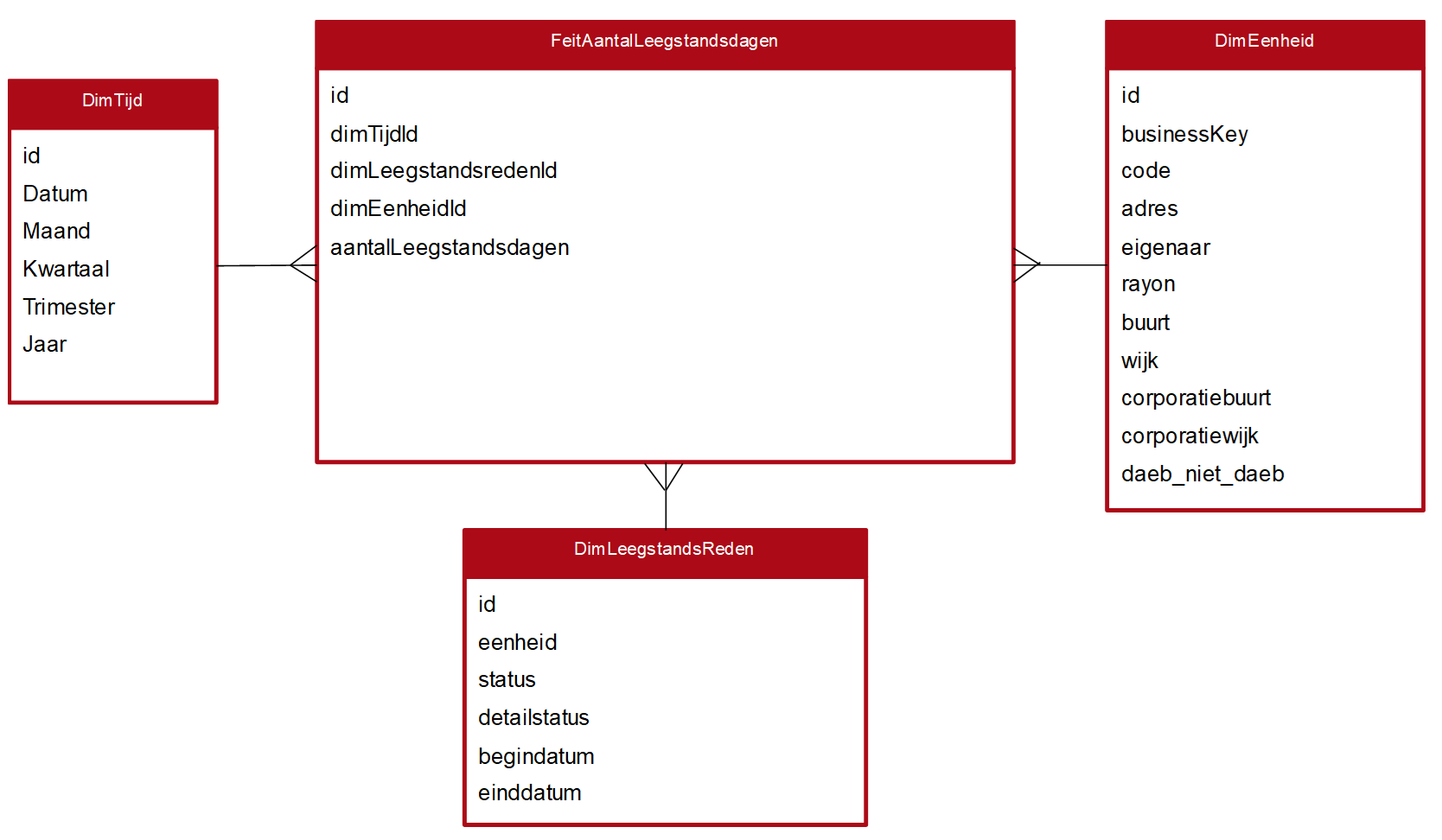 Figuur 16: Resulterende ster voor indicator AantalLeegstandsdagen.
Figuur 16: Resulterende ster voor indicator AantalLeegstandsdagen.
Stap 5: Berekening prestatie indicator[bewerken | brontekst bewerken]
De prestatie indicator wordt vervolgens berekend op basis van de in de microster aanwezige meetwaarden. Hiervoor moet een formule worden toegepast in de rapportagelaag. Ook hiervoor verwijzen we naar de bijlage met uitgewerkte prestatie indicatoren.
Toepassing in de praktijk[bewerken | brontekst bewerken]
De methodiek die hiervoor is uitgewerkt is een aanzet om te komen tot standaardisatie voor sturingsinformatie binnen VERA. De methodiek toont aan dat het standaardiseren van de gegevensoverdracht voor prestatie indicatoren kan plaatsvinden door het introduceren van een drietal adapters; de basisadapter, de Datakluis adapter en de ster adapter. Voor deze adapters wordt gebruik gemaakt van standaard VERA ingrediënten.
De adapters zijn logisch uitgewerkt. Om hiermee in de praktijk te kunnen werken moet meer worden geregeld. Er dienen ook technische keuzes te worden gemaakt. VERA gaat daar niet over. Wel geven we een paar adviezen en overwegingen voor toepassing in de praktijk.
De voorgestelde architectuur maakt gebruik van business keys. (Deze worden o.a. gebruikt in de hubtabellen van de Datakluis.) Op dit moment identificeert VERA echter nog geen business keys en ligt de keuze voor de key-attributen bij de gebruiker. Idealiter is deze keuze ook onderdeel van de VERA standaard.
Voor de gegevensoverdracht (push of pull) geven we een aantal mogelijkheden:
- Webservices: Niet de voorkeur, aangezien dit veel overhead geeft in het geval van bulkdata.
- CSV: Vanuit de operationele systemen wordt een set met CSV bestanden opgeleverd ten behoeve van rapportages. De set CSV bestanden bestaat uit bestanden conform het VERA datamodel. Per klasse één bestand.
- Databaseviews: De operationele systemen bieden middels een view laag toegang tot tabellen en velden, de viewlaag bevat views conform het VERA datamodel. Per klasse één view.
In Kennismodel[bewerken | brontekst bewerken]
Het thema PrestatiemetingVera past binnen de metastructuur van de CORA als weergegeven in onderstaande figuur, waarbij in het kennismodel alleen de concepten zijn ingekleurd die relevant zijn voor het thema PrestatiemetingVera:
Op dit moment bestaan er nog twee uitwerkingen van hoe we adviseren om prestaties meetbaar te maken. De CORA en de VERA methode. Ze kennen een enorme overlap en zullen in een volgende release als 1 aanpak worden gepresenteerd. Daarbij wordt de SBR-wonen terminologie leidend gemaakt.